Zaloguj
Zaloguj




Najnowszy procesor D32PRO to nowoczesny układ RISC, 32-bitowy, oferowany jako IP Core (w modelu bez opłat, tzw. royalty-free). Jego wydajność została udowodniona w strukturze krzemowej (silicon proven) - układ wykonano w procesie technologicznym 110 nm.
Procesor D32PRO ma zintegrowany koprocesor zmiennoprzecinkowy (FPC) oraz bogaty zestaw modułów peryferyjnych, jak np. USB, Ethernet, I²C, SPI, UART, CAN, LIN, RTC, HDLC, Smart Card etc. Dzięki temu pierwszy, polski, komercyjny procesor 32-bitowy stanowi atrakcyjną alternatywę dla dobrze znanych układów ARM Cortex M0/M0+/M1/M3, jak też i innych procesorów 32-bitowych oferowanych na rynku IP Core.
Architektura procesora D32PRO
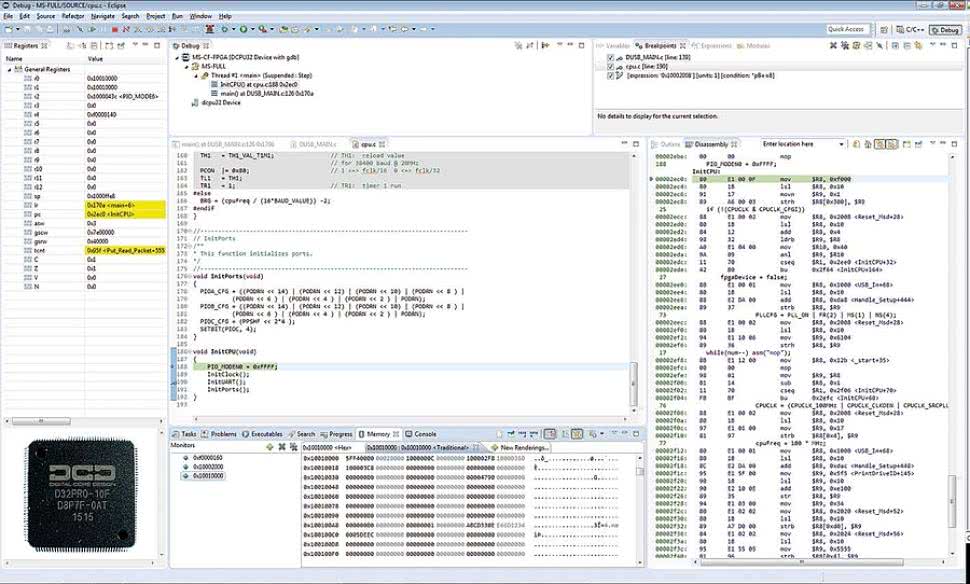
Rysunek 1. Procesor D32PRO jest obsługiwany przez środowisko Eclipse
D32PRO jest w pełni konfigurowalny. W zależności od potrzeb można wydatnie zmniejszyć powierzchnię zajmowaną przez procesor lub też zwiększyć jego wydajność. Z kolei dzięki zaawansowanej jednostce zarządzania energią (Power Management Unit), układ może być z powodzeniem zastosowany w aplikacjach energooszczędnych. W efekcie, zarówno typowe zastosowania, jak też i te związane z Internet of Things, Bluetooth Low Energy czy Wearables kreują szerokie spektrum zastosowań D32PRO.
Główną ideą przyświecającą inżynierom firmy DCD było zaprojektowanie procesora uniwersalnego i konfigurowalnego, nadającego się do zastosowania w różnorodnych aplikacjach. W D32PRO zaimplementowano autorską architekturę, która jest efektem optymalizacji maksymalnej częstotliwości zegara i opóźnienia w ścieżce danych.
Dzięki temu zbudowano uniwersalny procesor, który doskonale radzi sobie z wykonywaniem kodu z wieloma skokami, jak też i kodu jednolitego, pokroju operacji arytmetycznych. Nie byłoby to możliwe bez zastosowania zmiennej architektury potokowej.
Kolejne innowacje widoczne w D32PRO można dostrzec w liście rozkazów. Bazuje ona na specjalnie zaprojektowanych instrukcjach, które są maksymalnie zbliżone w swoim działaniu do konstrukcji języka wyższego poziomu, jak np. C.
W efekcie uzyskano bardzo dużą gęstość kodu, która jednocześnie idzie w parze ze zwartą i krótką listą rozkazów. Wśród nich można wymienić instrukcje pozwalające na optymalizację porównywania dwóch łańcuchów znaków czy też instrukcje znajdowania pierwszej jedynki w rejestrze.
Dla przykładu, można w tym miejscu wymienić instrukcję FZB pozwalającą na optymalizowanie wyszukiwania bajtów. W najprostszych procesorach 8-bitowych wyszukiwanie znaku NULL miało postać iterowania po wszystkich bajtach, na przykład:

|
W procesorach 32-bitowych zaczęto używać optymalizacji pozwalającej na jednoczesne sprawdzenie czterech bajtów rejestru:
DETECTNULL(X) (((X) - 0x01010101) & ~(X) & 0x80808080)
Jednakże o istotnym zwiększeniu wydajności można powiedzieć dopiero przy użyciu instrukcji FZB, która została zaimplementowana w D32PRO. Pozwala ona na przeszukanie rejestru za pomocą pojedynczej, jednocyklowej instrukcji
FZB $R0, $R1.
D32PRO jest wyposażony w 13 rejestrów ogólnego przeznaczenia R0...R12, spośród których większość zapewnia automatyczną aktualizację zawartości po powrocie z przerwania. Dzięki tej czynności znacznie przyspieszono obsługę przerwań czy przełączanie kontekstu w systemach czasu rzeczywistego.
Każdy ze wspomnianych rejestrów może być też użyty do operacji arytmetycznych, co jest o tyle przydatne, że jeśli odniesiemy to do klasycznego układu 8051 z łatwością zauważymy, że w pięćdziesiątkach jedynkach można było do tego wykorzystać tylko akumulator, co z kolei wiązało się koniecznością przeładowywania i zapisywania zawartości.
By jeszcze bardziej zwiększyć funkcjonalność procesora, wyposażono go w konfigurowalny układ przerwań zawierający 1 przerwanie niemaskowalne oraz do 32 przerwań maskowalnych. Sposób obsługi przerwania oraz jego detekcja są w pełni konfigurowane, dzięki czemu użytkownik może ustawić detekcję zbocza lub poziomu czy też konfigurować priorytety oraz sposób wejścia do obsługi przerwań.
Nowoczesne mikrokontrolery 32-bitowe powinny być projektowane ze szczególnym naciskiem na niski pobór energii. Nie inaczej rzecz ma się z D32PRO, który został wyposażony w zaawansowany system obniżania poboru energii. Moduł PMU (Power Management Unit) dynamicznie kontroluje częstotliwość zegara pozwalając na zaoszczędzenie energii w momencie, gdy nie jest wymagana maksymalna wydajność.
W D32PRO można konfigurować podzielnik zegara procesora oraz osobno podzielnik zegara modułów peryferyjnych. Dzięki temu nic nie stoi na przeszkodzie, by wprowadzić wyłącznie sam rdzeń w tryb energooszczędny, gdy tymczasem wymagane peryferia będą śledzić otoczenie z nominalnym zegarem.
Co więcej, sam rdzeń można także wprowadzić w tryb stop, w którym jest zatrzymywane taktowanie rdzenia, programując powrót do stanu normalnej pracy przez przerwanie od wybranych układów peryferyjnych. Procesor może także wyłączyć peryferia, które nie są używane w aplikacji, dzięki czemu można jeszcze bardziej zmniejszyć zapotrzebowanie na energię.
Na koniec nie sposób nie wspomnieć o debuggerze i bootloaderze, które wydatnie zwiększają komfort pracy z procesorem. Podobnie jak IP Core DCD z rodziny 8051, które mają wbudowany debugger sprzętowy DoCD, również i D32PRO ma zintegrowany debugger, który gwarantuje pełną kontrolę procesora z poziomu środowiska Eclipse (rysunek 1).
Kompletny system do projektowania składa się z: środowiska Eclipse, kompilatora GCC, kabka USB 2.0 i oczywiście - procesora D32PRO. Niepodważalną zaletą rozwiązania opracowanego przez inżynierów Digital Core Design jest fakt, iż do komunikacji debugger ten wykorzystuje tylko dwie linie, gdy konkurencyjne rozwiązania bazują najczęściej na interfejsie JTAG, który wykorzystuje standardowo 5 pinów.
Z kolei sprzętowy układ bootloadera pozwala na zapisanie pamięci programu firmware z zewnętrznej pamięci Flash za pomocą interfejsu SPI. Dodatkowo, bootloader jest wyposażony także w sprzętowy układ szyfrujący z kluczem zapisywanym w pamięci nieulotnej, co pozwala na zabezpieczenie firmware przed próbami nielegalnego odtworzenia.
DMIPS/MHz prawdę Ci powie?

Już nawet 8- czy 16-bitowe procesory zaczęły "osiągać" niewytłumaczalnie wysokie rezultaty wydajności. Nic więc dziwnego, że przywykliśmy do wyników rzędu 2-3 DMIPS/MHz dla procesorów 32-bitowych. Jednak czy są one realne? Czy procesor, który na papierze ma wydajność 2,5 DMIPS/MHz będzie równie wydajny przy wykonywaniu "codziennych" zadań? Niekoniecznie...
Wydajność D32PRO zmierzona za pomocą (i zgodnie z wytycznymi) wskaźnika Dhrystone wynosi 1,48 DMIPS/MHz. Tymczasem, gdy spojrzymy na rozwiązania firm konkurencyjnych (nazwijmy je A, B, C), zauważymy, że jej 32-bitowe procesory osiągają odpowiednio:
Procesor A: 1,53 DMIPS/MHz.
Procesor B: 1,79 DMIPS/MHz.
Procesor C: 2,83 DMIPS/MHz.
Jednakże, gdy przyjrzymy się procesorowi A, z łatwością zauważymy zwiększoną liczbę poziomów przy przetwarzaniu potokowym, co pozwala na pracę z dużą wydajnością. Należy jednak pamiętać, że warunkiem pracy z taką wydajnością jest jednolity kod (np. operacje arytmetyczne), jednak jeśli pojawiłyby się w nim skoki lub przerwania, ta wydajność spada.
Rzecz jasna, można temu zapobiec poprzez wykorzystanie układów predykcji czy pamięci cache, jednak wiąże się to z wydatnym zwiększeniem powierzchni zajmowanej przez CPU. Zatem należy podejść z dużą rezerwą do wysokich wyników Dhrystone, które idą w parze z relatywnie małą powierzchnią zajmowaną przez procesor. Zwiększenie wydajności odbywa się bowiem kosztem zwiększenia powierzchni i vice versa - zmniejszenie powierzchni układu powoduje wydatne ograniczenie jego możliwości.
Zestawienie wydajności 1,53 DMPIS/MHz z powierzchnią poniżej 10 tys. bramek ASIC sugeruje, że taką wydajność osiąga CPU, które zajmuje 10 tys. bramek. Nie jest to tak do końca prawdą, ponieważ podana najwyższa wydajność dotyczy procesora zawierającego wszystkie instrukcje - takie jak jednocyklowe mnożenie, przesuwanie, dzielenie i inne, natomiast sama powierzchnia w przytoczonym przykładzie podawana jest z usuniętym opcjonalnym "wyposażeniem".
Z kolei, jeśli przyjrzymy się np. procesorowi C zauważymy, że ma on 16, 24, i 32 bitowe instrukcje. Oznacza to, że na zapisanie rejestru 32-bitową stałą potrzeba dwóch instrukcji. Nie bez znaczenia jest fakt, że 24-bitowe instrukcje podnoszą stopień skomplikowania układu pobierania rozkazów, zwiększając zajmowaną powierzchnię i zapotrzebowanie na zużywaną energię. Dlatego też analizując wyniki wydajności poszczególnych procesorów, trzeba niestety dokonać dywersyfikacji na wyniki osiągane w programach takich jak Dhrystone oraz realną wydajność (podczas pracy).
Wykorzystanie popularnych kompilatorów wspierających optymalizacje na etapie linkowania, wypacza wyniki benchmarków dla dhry21. Jako przykład można podać np. GCC procesora A, B lub C, w którym z kodu wynikowego zupełnie wyrzucono dzielenie, mnożenie i znaczną część CALL/RET, a przy tym rozwinięto pętle.
Warto w tym miejscu nadmienić, że w dokumentacji z dhry21, który przecież został zaktualizowany do tej właśnie wersji w odpowiedzi na zbyt agresywną optymalizację - wyszczególniono dokładnie, że szybkość tych operacji wpływa na wartość DMIPS:

|
Jak więc widać, wyniki rzędu 2,5...3 DMIPS, które możemy odnaleźć w danych produktów konkurencyjnych, nie mają wiele wspólnego ze specyfikacją DMIPS. Idąc tym tropem, poprzez odpowiednią modyfikację kodu D32PRO można by osiągnąć wynik 3-4 DMIPS. Tylko jaki byłby sens takiego działania oprócz wyniku dobrze wyglądającego na papierze i w folderach reklamowych?
Często z kodu wynikowego usuwa się też mnożenie i dzielenie. Jest to związane z faktem, że w wynikach powyżej 2 DMIPS kompilator tak optymalizuje kod DHRY, że wykonuje operacje mnożenia i dzielenia, wpisując gotowe wyniki, jako stałe do wykonywanego kodu.
Tymczasem w rzeczywistym DHRY, jak też przede wszystkim w realnych aplikacjach - te operacje są wykonywane z użyciem odpowiednich instrukcji. Co więcej, wywołania funkcji w tak spreparowanych testach nie są wykonywane, bowiem ciało funkcji wstawiane jest bezpośrednio z głównej pętli (inline).
Eliminuje to instrukcje CALL/RET, które z reguły zajmują około 2-3 cykli każda. Ta czynność (inline) wpływa też na "ekstra optymalizację", ponieważ część operacji z tych funkcji "pokrywa się" i jest sklejana razem. W efekcie tak "zmodyfikowany" test daje wysokie wyniki DMIPS. Wracając do wcześniejszych rozważań można ponownie zapytać - dlaczego? Czy taki syntetyczny i zmodyfikowany wynik będzie mógł być użyty w realnej aplikacji? Odpowiedź jest oczywista.
Wbudowane peryferia kontra pełna konfigurowalność?

Fotografia 2. Płyta ewaluacyjna z układem FPGA, w którym zaimplementowano procesor D32PRO
D32PRO jest 32-bitowym, w pełni konfigurowalnym procesorem, oferowanym w modelu biznesowym royalty-free. Można powiedzieć, że jest to układ szyty na miarę, ponieważ w zależności od potrzeb można go dowolnie konfigurować, by osiągnąć pożądaną funkcjonalność.
Co ważne, zintegrowany koprocesor zmiennoprzecinkowy gwarantujący obsługę instrukcji zmiennoprzecinkowych IEEE-754 o pojedynczej precyzji, zapewnia stabilną, zoptymalizowaną pracę procesora. Z kolei, zintegrowany zestaw modułów peryferyjnych wraz ze sterownikami, pozwala na wydatne zwiększenie funkcjonalności całego rozwiązania, oferowanego pod nazwą D32PRO.
By dodatkowo ułatwić pracę z procesorem oraz zwiększyć możliwości implementacji, projektanci zadbali, aby był on niezależny technologicznie, dzięki czemu może być bez przeszkód wykorzystany zarówno w układach ASIC, jak i w FPGA.
Należy jednak podkreślić, że 32-bitowy procesor DCD jest rozwiązaniem silicon proven, którego sprawność potwierdzono w procesie technologicznym 110 nm. Jest przy tym oferowany w modelu royalty-free, dzięki czemu licencjobiorca nie ponosi żadnych dodatkowych opłat po zakupie licencji. Do tego otrzymuje 3-miesięczne, bezpłatne wsparcie techniczne, które może być rozszerzone na warunkach komercyjnych, na dowolny okres.
Procesor jest na tyle uniwersalny i wydajny, że nie można, a wręcz nie wolno wskazywać tylko jednego zastosowania. Rzecz jasna można tu wspomnieć o: IoT, urządzeniach medycznych, systemach sterowania w przemyśle, czytnikach kart płatniczych, Smart Electronic & Wearables i innych. Ale to zaledwie początek, wierzchołek góry lodowej możliwych aplikacji...
Procesor D32PRO zapewnia pełną konfigurowalność chociażby poprzez możliwość wyłączenia pewnych grup instrukcji, dzięki czemu można zmniejszyć powierzchnię procesora. Projektant może też wyłączyć nieużywane peryferia, bądź też wprost przeciwnie - skorzystać z bogatego zestawu modułów procesora, wśród których znajdziemy m.in. USB 2.0, Ethernet MAC, CAN, LIN, I²C, SP, CF & SD Card i inne.
Jeśli jednak i taki zestaw okazałby się dla kogoś niewystarczający, warto dodać, że D32PRO może być również dostarczony z pokazaną na fotografii 2 kompletną płytą ewaluacyjną FPGA, która wydatnie skróci czas testów i ułatwi pracę z procesorem.
Dzięki takiemu zestawowi inżynier nie musi konstruować własnego PCB, a następnie składać w całość poszczególnych elementów układanki. Wraz z D32PRO otrzymuje od Digital Core Design zestaw "all in one". Więcej informacji na www.dcd.pl.
Tomasz Ćwienk
Digital Core Design, tomasz.cwienk@dcd.pl