 Zaloguj
Zaloguj




Zagadnienia identyfikacji radiowej i optycznej tylko z pozoru stanowią tematy odległe – ich wspólnym celem jest bowiem szybki, bezbłędny i – w wielu przypadkach – całkowicie zautomatyzowany proces przekazywania niewielkich ilości informacji dotyczących określonego obiektu lub osoby. W zakresie metod optycznych mamy do czynienia z szerokim wachlarzem technik korzystających z drukowanych (lub wykonanych w innej formie stałej, na przykład za pomocą lasera) bądź wyświetlanych na ekranach oznakowania w postaci kodu paskowego. Pojęcie „kod paskowy” uległo w ostatnich latach znacznemu rozszerzeniu, gdyż określeniem tym nazywa się także dwuwymiarowe kody QR i inne o podobnej zasadzie kodowania informacji. W naszym przeglądzie zaprezentujemy najważniejsze informacje techniczne na temat rodzajów i konstrukcji kodów oraz urządzeń przeznaczonych do ich odczytywania.
Metody radiowe obejmują natomiast przede wszystkim trzy główne odmiany RFID, które – z uwagi na diametralne różnice w częstotliwości fali nośnej – tylko w pewnych przypadkach mogą być stosowane zamiennie, podczas gdy pozostała część aplikacji jest ściśle i nierozerwalnie związana z danym standardem przekazu informacji. W artykule omówimy zatem również najważniejsze rodzaje protokołów i fundamentalne zagadnienia techniczne, z którymi mierzą się konstruktorzy urządzeń wyposażonych w łączność RFID.
Obszary aplikacji
Zanim przejdziemy do szczegółów technicznych, spróbujmy ogólnie zarysować kilka głównych obszarów aplikacyjnych identyfikacji optycznej i radiowej.
Handel
Podstawowym i najczęściej wymienianym zastosowaniem kodów kreskowych jest rzecz jasna identyfikacja towarów w sklepach i hurtowniach – to właśnie handel odpowiada za intensywny rozwój i upowszechnienie kodów kreskowych, a rosnące potrzeby związane z ekspansją sklepów wielkopowierzchniowych wymusiły stosowanie coraz bardziej zaawansowanych metod odczytywania kodów w niezbyt sprzyjających warunkach – poszczególne opakowania (np. produktów spożywczych) różnią się kolorem i rodzajem powierzchni (błyszcząca lub matowa), geometrią (płaska, zaokrąglona), technologią naniesienia kodu kreskowego oraz jego rozmiarem, a wszystko to sprawia, że warunki akwizycji sygnałów optycznych zmieniają się nieustannie w bardzo szerokich granicach. Właśnie tutaj należy zatem upatrywać przyczyn powstania odpornych na artefakty, wielokierunkowych skanerów laserowych (fotografia 1), które na długo zagościły w kasach sklepowych, umożliwiając odczyt kodów, ustawionych w dowolnej orientacji względem obudowy czytnika.

Zastosowanie identyfikacji RFID w handlu detalicznym ma miejsce głównie w obszarze płatności zbliżeniowych – oprócz doskonale znanych wszystkim kart płatniczych i kredytowych, z dokładnie tej samej technologii (bazującej na NFC) korzystają również dostępne w niektórych bankach naklejki płatnicze, a także aplikacje mobilne, współpracujące z wbudowanym w większość współczesnych telefonów transceiverem NFC. Co ciekawe, niektóre instytucje udostępniły swoim klientom breloczki, bransoletki, a nawet… maskotki płatnicze (fotografia 2), przeznaczone dla najmłodszych użytkowników bankowości.

RFID jest także stosowane do zabezpieczenia cennych towarów przed kradzieżą, choć w tym przypadku mamy do czynienia z technologią nieporównanie prostszą niż klasyczne RFID z tagami wyposażonymi w scalone transpondery. Tu antena (fotografia 3) współpracuje z prostym układem LC, a obecność zabezpieczonego przedmiotu w obszarze bramki sklepowej jest wykrywana dzięki niewielkiemu zaburzeniu generowanego przez nią pola (na skutek rezonansu tagu z anteną nadajnika). Niektóre znaczniki są wyposażone w diodę, której celem jest podwojenie częstotliwości sygnału zwrotnego, dzięki czemu odbiornik może pracować w paśmie 2-krotnie wyższym niż pasmo sygnału pobudzającego. Dezaktywacja układu polega na zniszczeniu (przebiciu) kondensatora za pomocą odpowiednio silnego impulsu elektromagnetycznego. Technologia RFID stanowi jedną z trzech głównych odmian EAS (ang. Electronic Article Surveillance) obok metody akustyczno-magnetycznej oraz elektromagnetycznej.

Warto dodać, że fakt, iż kody kreskowe miały swój początek w świecie handlu detalicznego, szybko zaowocował stworzeniem szeregu organizacji i norm, których celem było ustandaryzowanie sposobów znakowania towarów. Amerykański system UPC (Universal Product Code) został ujednolicony z bazującym na nim, europejskim systemem EAN (European Article Number) przez globalną organizację GS1. Obecnie istnieje pokaźny zestaw norm opracowanych przez GS1, pokrywających wiele obszarów handlu i nie tylko – organizacja skupia się też na podniesieniu jakości opieki medycznej przez stosowanie automatycznej identyfikacji. Do tematyki standardów GS1 powrócimy jeszcze w dalszej części artykułu.
Logistyka
Drugim spośród najpowszechniejszych obszarów zastosowań kodów kreskowych jest szeroko pojęta logistyka i magazynowanie. Trudno wyobrazić sobie dostawców bądź pracowników sortowni, mozolnie wpisujących długie numery paczek na klawiaturze terminali kurierskich (fotografia 4) – błyskawiczna i bezbłędna identyfikacja paczek i kopert jest absolutnie niezbędna dla sprawnego transportu oraz dostarczania przesyłek.

Podobna sytuacja ma miejsce w przypadku wszelkich operacji magazynowych – przyjmowania, ewidencjonowania oraz wydawania towarów, niezależnie od wielkości przedsiębiorstwa. W tego typu aplikacjach stosuje się nie tylko konwencjonalne, ręczne skanery, ale także zaawansowane (manualne lub stacjonarne) systemy identyfikacji dalekozasięgowej. Niektóre modele są w stanie skanować kody na zaskakująco dużą odległość – przykładowo, komputer mobilny CipherLab 9700 może sczytywać kody o rozdzielczości 10 milsów z odległości do 15 cm, zaś przy 300 milsach zasięg dochodzi nawet do niemal 15 metrów (fotografia 5)!

Identyfikacja radiowa w przypadku zastosowań logistycznych obejmuje nie tylko bieżące monitorowanie i inwentaryzację stanów magazynowych, ale także śledzenie postępów transportu pojemników zbiorczych czy kontenerów wielokrotnego użytku. Tagi RFID pozwalają automatycznie rejestrować przepływ półproduktów i gotowych towarów przez cały proces logistyczny, bez konieczności celowania skanera optycznego na etykietę z kodem kreskowym. Co więcej – tematyka nie dotyczy tylko największych przedsiębiorstw i transportu morskiego, kolejowego czy też „dużej” spedycji. Dość powiedzieć o aplikacji systemu RFID w paśmie UHF przez sieć sklepów sportowych Decathlon, która od dawna dysponuje systemem metkowania produktów tagami RFID jeszcze przed opuszczeniem fabryki – dzięki zastosowaniu specjalnych terminali płatniczych towary znajdujące się w koszyku są automatycznie podliczane po jego umieszczeniu w obszarze czytnika, co zwalnia klienta z konieczności samodzielnego skanowania kolejnych kodów kreskowych. Technologia RFID UHF pełni w tym przypadku także funkcję systemu antykradzieżowego, znacznie ułatwia też inwentaryzację z użyciem czytników ręcznych (fotografia 6).

Medycyna
Aplikacje medyczne identyfikacji automatycznej stanowią doskonały przykład zastosowania technologii kodów kreskowych oraz RFID ze względu na ich niezawodność. Nietrudno wyobrazić sobie katastrofalne skutki zamiany leków przeznaczonych dla dwóch różnych pacjentów – w dobie zintensyfikowanej ochrony danych osobowych taka sytuacja byłaby wielce prawdopodobna bez zastosowania odpowiednich metod identyfikacji. Współczesne szpitale korzystają zatem z opasek nadgarstkowych z kodami kreskowymi (fotografia 7) bądź znacznikami RFID, zawierającymi najważniejsze dane pozwalające jednoznacznie zweryfikować tożsamość pacjenta.

Etykiety z kodami kreskowymi są także szeroko stosowane w diagnostyce laboratoryjnej do oznaczania próbek materiału biologicznego (np. krwi czy moczu – fotografia 8) oraz obsługi zleceń w laboratoriach komercyjnych – systemy teleinformatyczne pozwalają na bezbłędną identyfikację próbek i przypisywanie wyników do indywidualnych kont pacjentów lub tymczasowych kont tworzonych dla nowych klientów, co umożliwia samodzielne sprawdzenie wyników z poziomu przeglądarki internetowej.

Etykietowanie ma także ogromne znaczenie w farmacji (znakowanie leków), radiologii (automatyczne przypisywanie przenośnej kasety RTG do wykonywanego badania – w przypadku starszych systemów radiograficznych) oraz medycynie zabiegowej (opisy opakowań narzędzi chirurgicznych poddawanych sterylizacji – fotografia 9). Rzecz jasna, w każdym z tych zastosowań konieczne jest użycie etykiet dostosowanych do konkretnej aplikacji – opaski pacjentów powinny charakteryzować się dużą wytrzymałością mechaniczną (głównie na rozerwanie) i środowiskową (wodoodporność) oraz hipoalergicznością; etykiety stosowane w sterylizatorniach muszą natomiast przetrwać narażenie na wysoką temperaturę i wilgotność, panujące wewnątrz autoklawu.

Co ciekawe, w śledzeniu procesów dekontaminacji oraz sterylizacji sprzętu i wyposażenia medycznego (np. łóżek szpitalnych – rysunek 1) także stosowane są tagi RFID, choć w tym przypadku konieczne staje się użycie wyspecjalizowanych układów odpornych na niezwykle niesprzyjające warunki otoczenia (uszkodzenia mechaniczne podczas wstępnego czyszczenia, środki dezynfekujące czy też temperatura i wilgoć panujące w autoklawie).

Na rynku istnieją firmy zajmujące się produkcją takich właśnie znaczników – przykładowo, firma Xerafy opracowała hermetyczne znaczniki Dot XXS, pracujące w paśmie UHF (902–928 MHz dla rynku USA i 866–868 MHz do zastosowania w Europie). Te miniaturowe transpondery mają wymiary nieprzekraczające 4,38×2,58 mm, wytrzymują temperatury do 150°C i oferują klasę szczelności IP68 za sprawą obudowy zalanej żywicą epoksydową, dzięki czemu z powodzeniem można je zainstalować na rączce standardowego skalpela chirurgicznego (fotografia 10).

Nie sposób pominąć faktu, że zasięg tagów po umieszczeniu na metalowej powierzchni dochodzi aż do 50 cm, co jest nie lada wyzwaniem, zważywszy na rozmiary tagu oraz wpływ, jaki na zasięg komunikacji ma metalowa powierzchnia w pobliżu anteny RFID. Mało tego – niewiele większe tagi Dash XXS (fotografia 11) o wymiarach 6,75×2,08×2,08 mm osiągają prawie dwukrotnie większy zasięg transmisji, co pozwala na współpracę np. ze stacjonarnymi bramkami RFID.

Motoryzacja
Branża automotive także intensywnie korzysta z niezawodności i szybkości, jaką daje zastosowanie automatycznej identyfikacji produktów oraz komponentów. Zastosowanie RFID i kodów kreskowych generuje pełnię możliwości, które opisaliśmy już w części poświęconej logistyce (rejestracja przepływu komponentów i pojemników na każdym etapie produkcji – fotografia 12), a ponadto pozwala na szybką detekcję wadliwych egzemplarzy oraz śledzenie wszystkich innych elementów procesu (np. użycia narzędzi).

Branża samochodowa dorobiła się nawet własnego standardu, określającego najważniejsze rekomendacje dotyczące parametrów technicznych i zasad stosowania RFID w przemyśle motoryzacyjnym – dokument nosi oznaczenie VDA 5500 (VDA Basic Principles for RFID Application in the Automotive Industry), a ten odnosi się do czterech kolejnych norm, precyzujących zagadnienia związane z pojemnikami, śledzeniem komponentów czy też dystrybucją pojazdów:
- VDA 5501 – RFID for Container Management in the Supply Chain,
- VDA 5509 – AutoID/RFID-Application and Data Transfer for Tracking Parts and Components in the Vehicle Development Process,
- VDA 5510 – RFID for Tracking Parts and Components in the Automotive Industry,
- VDA 5520 – RFID in Vehicle Distribution.
Inne przykłady aplikacji
Oprócz wymienionych wyżej zastosowań istnieją też setki innych przykładów aplikacji RFID i kodów kreskowych – pokrótce wymieńmy zatem jeszcze kilka z nich:
- Obsługa eventów – jednorazowe opaski wyposażone w kody kreskowe (fotografia 13) bądź wbudowane tagi RFID są powszechnie stosowane jako szybkie w obsłudze i bezpieczne (tj. odporne na fałszerstwa) bilety na rozmaite eventy – koncerty, festiwale, pokazy multimedialne etc. Mogą one współpracować z ręcznymi czytnikami użytkowanymi przez obsługę bądź z automatycznymi bramkami.

- Kontrola dostępu – karty, breloki czy też bransoletki RFID są najczęściej stosowaną metodą kontroli dostępu (ale także np. rejestracji czasu pracy) w biurach, bankach, sklepach, urzędach, szpitalach, hotelach i innych instytucjach. Możliwość łatwej personalizacji tagów poprzez nadruki (wykonywane często przez ich dystrybutorów) pozwala zachować pełną zgodność z identyfikacją wizualną marki.
- Legitymacje – karty RFID niemal całkowicie zastąpiły dawne legitymacje studenckie, a nawet szkolne, dając nie tylko możliwość szybkiego dostępu do danych studenta (ucznia) w systemie informatycznym instytucji, ale także szereg dodatkowych funkcjonalności – przykładowo, pozwalają one zakodować bilety komunikacji miejskiej, zaś niektóre uczelnie wprowadzają aktywowane za pomocą legitymacji bramki wejściowe do budynków.
- Reklama wizualna – kody QR są powszechnie stosowanym sposobem na szybkie przekazywanie informacji, np. linków do stron internetowych, promocji lub fanpage’y – co więcej, ta forma reklamy bywa stosowana zarówno na opakowaniach niewielkich produktów, jak i na wielkoformatowych billboardach. Powszechnie stosowaną praktyką jest udostępnianie dodatkowych instrukcji użytkowania, wideotutoriali lub regulaminów, co pozwala zaoszczędzić ilość papieru zużywanego na druk akcesoriów, sprzedawanych wraz z urządzeniami powszechnego użytku.
- Parowanie urządzeń IoT – coraz częściej można spotkać się z zastosowaniem kodów QR do przyspieszonego parowania urządzeń, wykorzystujących łączność Bluetooth bądź Wi-Fi. Przykładem mogą być tutaj kamery IP – niektórzy producenci stosują kod naklejony na obudowę urządzenia (np. do identyfikacji numeru seryjnego – fotografia 14), a czasem dodatkowy kod wyświetlony na ekranie aplikacji mobilnej należy „pokazać” kamerze celem przekazania jej danych niezbędnych do nawiązania połączenia z lokalną siecią Wi-Fi (rysunek 2).


Identyfikacja optyczna 1D – podstawy techniczne
Podstawowym założeniem przyświecającym twórcom kodów kreskowych było zawarcie pewnej ilości informacji w formie możliwej do odczytu w sposób całkowicie zautomatyzowany. Zabieg taki wymagał maksymalnego uproszczenia reprezentacji znaków – naturalną konsekwencją było zatem użycie tylko dwóch poziomów jasności (w idealnym przypadku – czerni i bieli), które dają możliwie największy kontrast optyczny podczas skanowania.
Kolejną kwestią techniczną, którą należało rozwiązać, był sposób zapisu oraz odczytu informacji. Aby (za pomocą pojedynczego fotoelementu) przekonwertować ciąg czarno-białych pasków na odpowiadający im sygnał w domenie czasu, trzeba zapewnić sukcesywne skanowanie kolejnych miejsc kodu kreskowego, co można zrealizować najprościej poprzez ruch liniowy w poprzek kodu. Istnieje zatem kilka możliwości realizacji tego zadania:
- przesunięcie całego kodu przed detektorem (oświetlacz i detektor są stacjonarne, porusza się tylko skanowany obiekt),
- jednostajne przesunięcie detektora punktowego nad kodem (kod, a więc też obiekt pozostają stacjonarne, zaś porusza się zespół detektora wraz z oświetlaczem),
- przesunięcie punktu świetlnego po powierzchni kodu (obiekt i detektor pozostają nieruchome, zaś porusza się jedynie wąska wiązka światła).
Wynalazcy kodu kreskowego i pierwszego przeznaczonego dla nich czytnika – Norman Joseph Woodland oraz Bernard Silver – zdecydowali się na zastosowanie pierwszej z opisanych technik. Zgłoszenia patentu na swoje – niezwykle innowacyjne jak na owe czasy – rozwiązanie dokonali w 1951 roku, zaś amerykańskie prawo ochronne o numerze US2612994 otrzymali rok później.

W dokumencie znajdujemy opis prostego kodu kreskowego (rysunek 3) oraz urządzenia odczytującego, bazującego na… przezroczystym przenośniku taśmowym, transportującym odpowiednio ułożone towary nad zespołem czytnika optycznego (rysunek 4). Choć nietrudno dziwić się, że rozwiązanie to zostało wyparte przez skanery laserowe, to zdecydowanie utorowało ono drogę nowej technologii automatycznej identyfikacji.
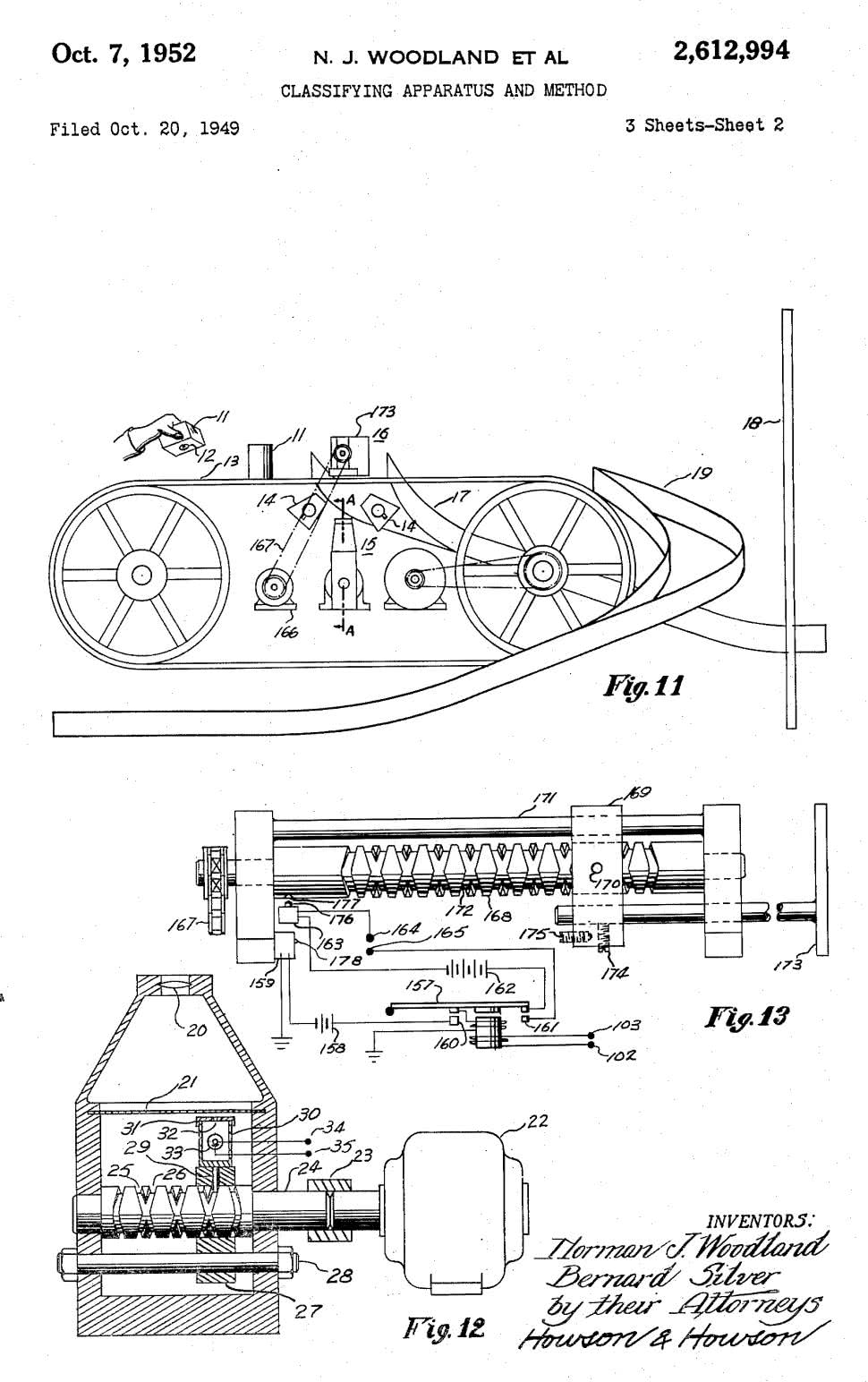
Znając wspomniane trzy konfiguracje, pozwalające na uzyskanie efektu skanowania, można łatwo wyobrazić sobie ich realizacje praktyczne.
Skanery typu pen (in. wand) zawierają niewielką, sferyczną soczewkę, umieszczoną na końcu obudowy o kształcie zbliżonym do długopisu (fotografia 15) i współpracującą z fotodetektorem oraz oświetlaczem. Ruch w poprzek kodu kreskowego jest zatem realizowany manualnie i wymaga od użytkownika utrzymania stosunkowo stałej szybkości przesuwu czujnika. Czytniki tego typu są urządzeniami kontaktowymi, co oznacza, że soczewka musi dotykać powierzchni kodu w czasie skanowania.

Skanery laserowe (konwencjonalne) – zastosowanie lasera półprzewodnikowego jako energooszczędnego i kompaktowego źródła światła o silnie skolimowanej wiązce spowodowało prawdziwą rewolucję w świecie czytników kodów kreskowych. Obecnie najczęściej spotykaną konstrukcją jest układ optyczny z drgającym zwierciadłem, napędzanym przez niewielki elektromagnes. Odpowiednia geometria układu optycznego, zawierającego także drugie, statyczne zwierciadło, umożliwia uzyskanie szerokiego kąta skanowania przy stosunkowo niewielkiej amplitudzie oscylacji. Rzecz jasna, w celu prawidłowego odczytania kodu konieczne jest zastosowanie sprzężenia zwrotnego, pozwalającego na weryfikację położenia i odpowiednie sterowanie ruchem zwierciadła.
W praktyce stosowane są dwie główne odmiany konstrukcji części mechanicznej skanerów laserowych. Pierwsza z nich zawiera obrotowy element w postaci dźwigni dwustronnej, która na jednym końcu ma zamontowane zwierciadło, zaś na drugim – magnes stały, tworzący wraz z pobliskim elektromagnesem niewielki aktuator (fotografia 16).

Inna koncepcja, stosowana m.in. w popularnych skanerach Voyager, bazuje na części ruchomej, złożonej ze zwierciadła przyklejonego do (zamocowanej jednostronnie) metalowej płytki elastycznej (fotografia 17). Zasilenie elektromagnesu przebiegiem prostokątnym o częstotliwości zbliżonej do częstotliwości rezonansowej układu blaszka-zwierciadło powoduje wprowadzenie całości w rezonans mechaniczny, co zapewnia stabilne drgania układu, bez konieczności stosowania jakichkolwiek przegubów obrotowych. Warto dodać, że praca w rezonansie mechanicznym wymaga pewnego czasu na ustabilizowanie drgań po włączeniu zasilania – efekt ten można zauważyć tuż po uruchomieniu skanera, obserwując linię tworzoną przez wiązkę laserową na płaskim podłożu.

Skanery laserowe wielokierunkowe stanowią modyfikację konwencjonalnego skanera, polegającą na rozbudowie o zestaw dodatkowych zwierciadeł, umożliwiających uzyskanie zestawu linii świetlnych zamiast pojedynczego odcinka. Producenci stosują także specjalne techniki, pozwalające na zwiększenie pokrycia obrazowanej powierzchni liniami światła laserowego – ciekawy przykład można zaobserwować w odcinku 637 znanego videobloga EEVblog (https://t.ly/Ep_B). Pokazany na filmie skaner Symbol LS9208 marki Motorola zawiera pięć zwierciadeł płaskich ustawionych radialnie wokół ruchomego zwierciadła – odpowiadają one za odchylanie wiązek pod różnymi kątami. Obrotowe, czworoboczne zwierciadło o zróżnicowanym nachyleniu ścianek jest synchronizowane za pomocą znajdującego się na płytce drukowanej transoptora odbiciowego, a kolejne – w tym przypadku drgające – zwierciadło ma za zadanie dodatkowo „wypełniać” badany obszar pomiędzy liniami tworzonymi przez zwierciadło obrotowe. Widok wnętrza urządzenia pokazano na fotografii 18.

Białe krążki umieszczone w czterech narożnikach całego zespołu skanera stanowią amortyzację, chroniącą czułą optykę urządzenia przed drganiami, przenoszonymi poprzez obudowę. W urządzeniu zastosowano także szereg innych, interesujących rozwiązań technicznych – Czytelników zainteresowanych szczegółami jego konstrukcji zachęcamy do obejrzenia przytoczonego odcinka na kanale EEVblog.

Opisany wcześniej skaner symbol LS9208 generuje podstawowy wzór 5 zestawów linii równoległych (po 4 na każdy z nich), rzutowanych pod różnymi kątami (fotografia 19) i dodatkowo przesuwanych przez drgające zwierciadło. Warto jednak wiedzieć, że producenci skanerów wielokierunkowych stosują często także zupełnie inne przebiegi wiązek laserowych – przykłady pokazano na rysunku 5. W każdym przypadku celem takich zabiegów jest umożliwienie odczytania kodów o różnych rozmiarach, umieszczonych pod dowolnym kątem względem obudowy skanera.

Czytniki CCD bazują na całkowicie innych założeniach, niż opisane powyżej skanery laserowe. W tym przypadku mamy bowiem do czynienia z urządzeniami w pełni statycznymi – brak tutaj jakichkolwiek elementów ruchomych, a nawet… samego lasera, gdyż akwizycja obrazu odbywa się w świetle zastanym (oświetlenie zewnętrzne lub światło emitowane przez ekran, wyświetlający kod kreskowy) bądź w rozproszonym świetle wbudowanego iluminatora LED, wyposażonego w stosowne kolimatory. Obraz kodu jest rzutowany przez obiektyw na linijkę fotoelementów CCD, zatem wynikiem akwizycji jest tutaj nie sygnał napięcia w dziedzinie czasu, ale… obraz o wysokości jednego piksela i szerokości równej rozdzielczości zastosowanego liniału CCD. Takie rozwiązanie, pozbawione napędów oraz (drgających i statycznych) zwierciadeł, pozwala na znaczną miniaturyzację czytników, czyniąc tę technologię doskonałym wyborem dla producentów modułów OEM. Przykład tego typu zespołu pokazano na fotografii 20.

Rodzaje kodów kreskowych (1D)
Kilka dekad rozwoju technik identyfikacji optycznej doprowadziło do powstania dziesiątek odmian kodów kreskowych. Niektóre z nich są uniwersalne i przyjęły się w wielu branżach, inne pozostają domeną wąskiej grupy specjalistycznych aplikacji. Poniżej prezentujemy wybór kilku spośród najczęściej spotykanych kodów jednowymiarowych.
- EAN-13 – najczęściej używany w globalnym handlu, 13-cyfrowy kod wykorzystywany do numerowania produktów o określonej masie bądź pojemności. W ramach kodu EAN-13 zapisany jest numer GTIN-13, będący identyfikatorem danego produktu. Na początku numeru znajduje się trzycyfrowy kod kraju (np. 590 dla produktów polskich), kolejne bloki (o zmiennej długości) kodują nazwę producenta oraz konkretne produkty – wyjątkiem jest ostatnia cyfra, pełniąca funkcję sumy kontrolnej. Skrócona odmiana EAN-13
(EAN-8) jest stosowana na produktach o niewielkich wymiarach opakowania. - UPC-A – kod stosowany w handlu amerykańskim i kanadyjskim, był podstawą do opracowania EAN-13. Od strony technicznej (sposób kodowania cyfr i liczenia sumy kontrolnej) jest identyczny, a różnica jest widoczna tylko w graficznym ułożeniu numerycznej reprezentacji identyfikatora towaru, stanowiącej „podpis” umieszczony poniżej właściwego kodu. Dodatkowa cyfra na początku kodu EAN-13 (i zapisana poprzez sposób kodowania lewej grupy cyfr) pozwala bowiem rozszerzyć zakres numeracji na inne kraje świata (dla USA i Kanady ma ona wartość zero). Porównanie obydwu opisanych powyżej systemów pokazano na rysunku 6. Podobnie jak w przypadku EAN-13, także UPC-A doczekał się swojej skróconej wersji, oznaczonej UPC-E.

- Code 39 – inaczej kod „3 z 9”, w podstawowej wersji pozwala na zapis (łącznie 43) znaków alfanumerycznych (cyfry oraz wielkie litery) i kilku znaków specjalnych (spacja, ‘-’, ’.’, ’$’, ’/’, ’+’, ’%’ oraz ‘*’), choć istnieje także wersja Code 39 plus, pozwalająca na zakodowanie 128 znaków z tablicy ASCII (poprzez zastosowanie sekwencji dwuznakowych). Długość kodu 3 z 9 nie jest formalnie ograniczona. Co ważne, pierwszy oraz ostatni znak to „*” – są one używane do określenia kierunku skanowania. Wadą kodu 39 jest mała gęstość zapisu danych, co oznacza, że zapisanie dłuższego ciągu znaków okazuje się niemożliwe przy niewielkiej ilości miejsca na etykietowanym przedmiocie.
- Code 128 – wspomnianej powyżej wady pozbawiony jest kod 128, zaprojektowany do obsługi ciągów alfanumerycznych oraz znaków specjalnych i oferujący większą gęstość zapisu danych. Po znaku startu następuje ciąg danych (znaków ASCII), suma kontrolna oraz znak stopu, przy czym zapis ciągu ASCII może wykorzystywać jedną z trzech „palet”, oznaczonych skrótami 128A, 128B oraz 128C. Kod 128 jest szeroko stosowany w ogólnoświatowej branży transportowej.
- PHARMA-CODE – binarny kod kreskowy, którego marka jest własnością firmy Laetus. Stosowany od wielu lat w przemyśle farmaceutycznym do znakowania opakowań oraz ulotek leków w celu kontroli jakości druku i poprawności pakowania. Pozwala na zapisanie liczby całkowitej w zakresie dziesiętnym od 3 do 131070 (czyli – binarnie – od 0x3 do 0x1FFFE). Warto zwrócić uwagę, że każdy dopuszczony do użytku lek ma dodatkowe oznaczenia, widoczne na zakładkach kartonowego opakowania, brzegach ulotek, etc. (fotografia 21) – zastosowanie odpowiednich czytników w procesie pakowania (fotografia 22) pozwala zweryfikować nie tylko, czy informacje na opakowaniu zostały wydrukowane poprawnie (np. pod względem odwzorowania kolorów), ale także, czy nie wystąpiły błędy w kompletacji.


Nietrudno sobie wyobrazić, jak krytycznie ważne dla bezpieczeństwa pacjentów jest uniknięcie sytuacji, w której lek o danym stężeniu substancji czynnej jest pakowany w pudełko (lub wyposażony w ulotkę), przeznaczone dla wersji o zupełnie innym stężeniu, a nawet – dla diametralnie innego farmaceutyku. Od pewnego czasu można zauważyć, że wiele firm rezygnuje ze stosowania PHARMA-CODE na rzecz kodów dwuwymiarowych (głównie Data Matrix), pozwalających na zapisanie większej ilości informacji (fotografia 23).

W użyciu jest jednak znacznie więcej odmian kodów kreskowych, nierzadko przeznaczonych do bardzo wąskiej grupy zastosowań – na rysunku 7 można zobaczyć niektóre z nich.

Anatomia kodu kreskowego
Jak już wspomnieliśmy, poszczególne rodzaje kodów kreskowych diametralnie różnią się pod względem sposobu kodowania poszczególnych znaków, a więc – co za tym idzie – także gęstości zapisu danych, możliwości wykrywania lub minimalizowania ryzyka błędów odczytu, etc. Nie sposób zatem podać jednego, uniwersalnego opisu pozwalającego zrozumieć budowę wszystkich stosowanych w praktyce systemów identyfikacji optycznej. Dlatego w artykule omówimy pokrótce sposób konstrukcji kodów EAN-13 jako doskonały (choć w żadnym wypadku nie uniwersalny) przykład metodologii znakowania paskowego.

Na rysunku 8 pokazano przykładowy kod EAN-13, za pomocą którego zapisano identyfikator 8 711253 00120 wraz z sumą kontrolną (ostatnia cyfra 2). Pierwszy z trzynastu znaków decyduje o sposobie zapisu kolejnych cyfr – podczas gdy lewa grupa (711253) stosuje zapis kolejnych cyfr według kodowania parzystego (even – oznaczonego jako G) lub nieparzystego (odd – oznaczonego jako L), to prawa grupa (001202) zawsze jest zapisywana z użyciem kodowania parzystego (R – patrz tabela 1).

Zapis poszczególnych cyfr od 0 do 9 według kodowań G, L i R zaprezentowano na rysunku 9 – każdy znak składa się z odpowiedniego ułożenia dwóch pasków czarnych o różnych szerokościach, przy czym „rozdzielczość” każdego znaku wynosi 7 (innymi słowy – każdy znak jest kodowany przez zestaw o szerokości równej 7-krotności najcieńszego możliwego paska czarnego lub białego). Taki pozornie skomplikowany sposób zapisu umożliwia oprogramowaniu czytnika rozpoznanie kierunku danych – pierwszy znak z lewej grupy zawsze ma kodowanie nieparzyste (L), zaś z prawej – parzyste (R). Co więcej, kod zapewnia kompatybilność z UPC-A – w przypadku, gdy pierwsza cyfra identyfikatora ma wartość zero (w naszym przykładzie jest to 8, dlatego od razu widać, że mamy do czynienia z EAN-13), cała lewa grupa cyfr jest zapisana z użyciem kodowania nieparzystego (dokładnie tak, jak wymaga tego kod UPC-A). Podwójne kreski o jednostkowej szerokości, umieszczone na początku i końcu oraz w środku kodu, stanowią markery kontrolne. Dodatkowo, poza markerami granicznymi należy umieścić pustą przestrzeń (w kolorze tła kodu, np. białym), stanowiącą niezbędny w przypadku prawie wszystkich kodów kreskowych obszar „ciszy” (ang. quiet zone).

Suma kontrolna w przypadku kodów EAN-13 jest liczona poprzez zsumowanie iloczynów kolejnych cyfr identyfikatora (od pierwszej do dwunastej) z wagami, ułożonymi na przemian (1,3,1,3,1,3,…), a następnie zaokrąglenie uzyskanej liczby w górę i obliczenie różnicy oryginalnej sumy ważonej z jej zaokrągloną wersją. Dla naszego przykładowego kodu otrzymamy zatem następujące obliczenia:
Suma ważona: 8·1+7·3+1·1+1·3+2·1+5·3+3·1 +0·3+0·1+1·3+2·1+0·3=58
Zaokrąglenie sumy: 60
Różnica: 60–58=2
Identyfikacja optyczna 2D – podstawy techniczne
Upowszechnienie urządzeń mobilnych, wyposażonych w doskonałej jakości kamery, a także rozwój czytników bazujących na wysokorozdzielczych matrycach CMOS/CCD i zaawansowanych algorytmach wizyjnych spowodowały znaczny wzrost zainteresowania kodami dwuwymiarowymi, które – już przy niewielkich rozmiarach – mogą przechowywać nieporównanie więcej informacji niż kody jednowymiarowe. Także w tym przypadku istnieje szereg standardów zapisu danych, choć liczba używanych w praktyce kodów jest nieporównanie mniejsza niż w przypadku kodów 1D.
Budowa czytników 2D
Skanowanie laserowe, które doskonale sprawdza się w odniesieniu do klasycznych kodów kreskowych (w dosłownym znaczeniu), nie sprawdziłoby się w świecie kodów 2D – dlatego też współczesne czytniki bazują na szybkich matrycach o odpowiednio wysokiej rozdzielczości, a także wbudowanych oświetlaczach LED i wydajnych procesorach wizyjnych. Zastosowanie kamer pozwala na pracę zarówno z kodami wyświetlanymi na ekranach (najczęściej urządzeń mobilnych), jak i wydrukowanymi lub wytworzonymi w inny sposób (np. za pomocą znakowania laserowego). Zmiana podejścia do odczytywania kodów powoduje zatem, że istnieje możliwość znacznego zminiaturyzowania czytników (nie wymagają one bowiem żadnych elementów ruchomych), czego dowodem są kompaktowe moduły OEM – np. model Superlead 2102N (fotografia 24). W module o wymiarach zaledwie 21×15×12 mm zmieściła się nie tylko kamera o rozdzielczości 640×480 px, ale także podwójny system oświetlaczy i wbudowany procesor wizyjny, obsługujący kody jednowymiarowe (UPC, EAN, Code 128, Code 39, Code 93, DataBar i in.) o rozdzielczości rzędu 4 milsów (!) oraz dwuwymiarowe (QR Code, PDF417, Data Matrix, Maxi Code, Aztec i inne).

Warto dodać, że – o ile w przypadku czytników laserowych wiązka oświetlająca stanowiła jednocześnie marker pozwalający na łatwe wycelowanie urządzenia w odczytywany kod – o tyle w przypadku urządzeń 2D wymagane jest do tego celu dodatkowe źródło światła.
Dlatego też w większości czytników – oprócz właściwego iluminatora, pozwalającego na pracę z kodami drukowanymi w warunkach słabego oświetlenia zewnętrznego – stosowany jest także dodatkowy układ, bazujący na laserze półprzewodnikowym bądź diodzie LED z odpowiednim kolimatorem, służący do rzutowania na środek pola obrazowania niewielkiego znacznika (najczęściej kółka lub krzyża) i nazywany mianem celownika (ang. aimer). Zastosowanie celownika jest bardzo istotne zwłaszcza w przypadku etykiet zawierających kilka kodów w niewielkiej odległości od siebie (np. naklejek umieszczanych przez dystrybutorów komponentów elektronicznych na torebkach strunowych). W wielu urządzeniach występuje ponadto dodatkowy oświetlacz (zwykle w postaci zielonej diody LED), rzutujący na sczytywany kod plamkę światła, będącą potwierdzeniem poprawnego zeskanowania identyfikatora (fotografia 25).

Rodzaje kodów 2D
W praktyce stosowanych jest najczęściej pięć głównych odmian kodów 2D, które pokrótce omówimy poniżej (rysunek 10).

- QR Code – zdecydowanie najczęściej spotykany w codziennym życiu standard identyfikacji optycznej, wynaleziony w 1994 roku przez japońskiego inżyniera Masahiro Hara z firmy Denso Wave. Można wyróżnić 40 wersji, różniących się rozmiarami – liczba modułów w każdej osi macierzy (czyli – najprościej rzecz ujmując – jednostkowych „pikseli” kodu) – wynosi N×4+17, gdzie N to numer wersji; przykładowo, kod w wersji 3 ma wymiary 29×29 modułów. Zastosowanie jednego z czterech poziomów korekcji błędów metodą Reeda–Solomona pozwala – kosztem nieco większych wymiarów – odtworzyć nawet poważnie uszkodzony kod. Zachęcamy naszych Czytelników do przetestowania kodu umieszczonego na fotografii 26 za pomocą jednego z darmowych skanerów QR w postaci aplikacji mobilnych.

- Data Matrix – drugi spośród najczęściej stosowanych kodów 2D, szeroko wykorzystywany w zastosowaniach przemysłowych z uwagi na dużą gęstość upakowania danych – stąd też kod można spotkać na niewielkich opakowaniach leków (np. dozownikach), płytkach drukowanych (fotografia 27), małych urządzeniach, komponentach elektronicznych (warto zajrzeć do normy EIA 706 – Component Marking) czy też rozmaitych podzespołach samochodowych, a nawet kosmicznych (dociekliwym Czytelnikom zwracamy uwagę na standardy AS9132, NASA-STD-6002 oraz NASA-HDBK-6003). Z uwagi na szeroki zakres zastosowań, kody Data Matrix często wykonuje się za pomocą technik innych niż normalny wydruk – np. poprzez znakowanie laserowe (fotografia 28) lub mikroudarowe (fotografia 29).



- PDF417 stanowi przykład kodu piętrowego, mającego charakterystyczne sekwencje startu i stopu oraz 1…30 modułów danych (określanych jako codewords), otoczonych przez dwa moduły informujące nt. liczby wierszy czy też poziomu zastosowanej korekcji błędów. W odróżnieniu od Data Matrix, PDF417 nie nadaje się do wytwarzania metodami mechanicznymi bezpośrednio na powierzchni znakowanych detali – stąd też najczęściej kody tego typu są drukowane konwencjonalnymi metodami.
- MaxiCode to standard opracowany i używany przez firmę kurierską UPS do znakowania paczek. Zawiera charakterystyczną sekwencję koncentrycznej „tarczy”, stanowiącej centralny znacznik pozwalający na szybką lokalizację kodu na etykietach przesyłek transportowanych za pomocą przenośników. Strukturę kodu opisuje międzynarodowy standard ISO/IEC 16023:2000.
- Aztec – główną zaletą tego rodzaju kodu 2D jest brak wymogów co do stosowania pustego otoczenia wokół symbolu (quiet zone). Także w tym przypadku (podobnie jak w standardzie MaxiCode) mamy do czynienia z centralnym znacznikiem, całość ma jednak formę ortogonalnej macierzy przypominającej strukturę kodów QR oraz Data Matrix. Kody Aztec są stosowane m.in. w polskich dowodach rejestracyjnych pojazdów.
Anatomia kodu QR
Podobnie jak w przypadku kodów jednowymiarowych, teraz podamy skrót najważniejszych informacji o „anatomii” przykładowego standardu 2D – przyjrzymy się budowie kodu QR.

Na rysunku 11 zaprezentowano najważniejsze strefy wymagane w kodzie QR w wersji 7 (45×45 modułów). Strefa „ciszy” (zielony obszar) powinna mieć szerokość przynajmniej 4 modułów z każdej strony kodu. Trzy kwadratowe znaczniki pozycji są umieszczone w rogach kodu, zaś dodatkowe markery wyrównujące – w zależności od rozmiaru (wersji) kodu – w równej macierzy „zsynchronizowanej” geometrycznie z wewnętrznymi krawędziami znaczników pozycyjnych. Dodatkowo, w kodzie „zaszyte” są informacje o tzw. timingu (pozwalające oprogramowaniu wizyjnemu na narzucenie niezbędnego do dalszej analizy układu kartezjańskiego) oraz jego wersji (niebieskie pola obok leżących po przekątnej znaczników pozycyjnych) i formacie (czerwone obszary obok wszystkich markerów pozycji).
Pozostały obszar kodu (zaznaczony kolorem szarym) mieści właściwe dane oraz kody korekcji błędów.

Ułożenie danych w obszarze poza opisanymi wcześniej strefami specjalnymi jest dość intuicyjne (rysunek 12). Jak widać, każdy znak kodu jest zapisywany w formacie 8-bitowym według jednej z czterech możliwych konfiguracji, zależnych od położenia danego elementu na drodze wirtualnej „ścieżki odczytu”. Dodatkowe pole (Len) pozwala na zakodowanie długości danych. Warto dodać, że w zależności od wybranego formatu kody QR mogą pracować także z danymi alfanumerycznymi, liczbowymi bądź ze znakami Kanji oraz Kana, przy czym w celu zapisu znaków o liczbie bitów różnej od 8 stosowane są odpowiednie metody konwersji i uzupełniania.
Kody trójwymiarowe, czyli dlaczego nie należy bezgranicznie ufać „internetom”
Zagłębiając się w tematykę kodów kreskowych, można zauważyć spore nieścisłości w opisie rzadziej spotykanych odmian kodów. Jak to zwykle bywa w przepastnych zasobach internetowych, niektóre źródła podają całkowicie sprzeczne informacje dotyczące kodów trójwymiarowych i – żeby było jeszcze ciekawiej – istnieją znaczne różnice pomiędzy sposobem zaliczania konkretnych metod identyfikacji do grupy kodów 3D. Wszystkie wspomniane problemy wynikają jednak z niedostatecznego zrozumienia tej tematyki.
Dość powiedzieć, że niektórzy zaliczają do kodów 3D na przykład standard… QR Code (sic!). Inni tym samym mianem określają kody wielokolorowe, stanowiące np. złożenie trzech różnych, monochromatycznych kodów QR (np. czerwonego, zielonego i niebieskiego) w celu zwiększenia pojemności danych. Jeszcze inni do grupy kodów 3D zaliczają… opisane wcześniej wersje kodów 2D, ale utworzone za pomocą mechanicznych technik bezpośredniego znakowania (ang. DPM – Direct Part Marking), prowadzących do powstawania kodów o powierzchni nieznacznie wklęsłej (patrz fotografia 29). Wszystkie te próby klasyfikacji kodów kreskowych są rzecz jasna całkowicie błędne – jeszcze raz podkreślamy, że o wymiarowości kodu świadczy jego rzeczywista geometria, powiązana ze sposobem odczytu. Nawet jeżeli kod wykonany metodą mikroudarową faktycznie składa się z niewielkich zagłębień w powierzchni znakowanego detalu, to i tak odczytuje się go metodami optycznymi za pomocą kamer o dwuwymiarowych (X, Y) matrycach. O prawdziwych kodach 3D moglibyśmy zatem mówić jedynie w przypadku, gdyby dane były zapisywane w dwuwymiarowej macierzy (X, Y), wypełnionej modułami o zmiennej wysokości (Z), która to wysokość też sama w sobie niosłaby pewną ilość informacji – wymagałoby to jednak diametralnie innych metod odczytu. Na marginesie warto dodać, że w niektórych zaawansowanych aplikacjach stosuje się już kody korzystające z subtelnych różnic wysokości powierzchni – idea przyświecająca twórcom takich rozwiązań jest nieco zbliżona do budowy kluczy, współpracujących z zamkami antywłamaniowymi.
Kody 2D vs markery Aruco
Warto wspomnieć nieco o markerach optycznych, służących do automatycznej identyfikacji punktów odniesienia na obrazach obiektów (np. płytek drukowanych), przetwarzanych z użyciem systemów wizyjnych. O ile w prostszych przypadkach w zupełności wystarczające okazują się nieskomplikowane markery (przykład na fotografii 30), o tyle w bardziej zaawansowanych systemach konieczne okazuje się użycie markerów przypominających nieco opisane wcześniej kody 2D (np. QR czy Data Matrix).

Jednymi z najpopularniejszych są markery z rodziny ArUco (rysunek 13). Ich niekwestionowaną zaletą jest fakt, że same w sobie – w przeciwieństwie np. do markerów koncentrycznych stosowanych na PCB – niosą binarną informację, pozwalającą jednoznacznie je zidentyfikować.

Znaczniki takie ułatwiają zatem precyzyjne określenie np. orientacji obrazowanej sceny względem matrycy kamery – (fotografia 31). Cecha, która odróżnia je od wcześniej omówionych kodów 2D, leży jednak w zawartości danych – podczas gdy w niemal wszystkich wypadkach czytnik kodów 2D pracuje z oznakowaniem wcześniej mu nieznanym (a rozpoznaje go dzięki algorytmom ustalającym format zapisu), to systemy wizyjne korzystające z markerów ArUco (lub podobnych) szukają na obrazie symboli z predefiniowanego słownika.

Technologie radiowe – podstawy techniczne
Świat technologii RFID dzieli się na trzy główne obszary, zaś czynnikiem jednoznacznie je rozgraniczającym jest pasmo transmisji. Choć w sieci można natknąć się na informacje o tagach i czytnikach pracujących w mniej popularnych przedziałach widma częstotliwości, to zdecydowanie najczęściej mamy do czynienia z zakresami LF, HF oraz UHF. Ogólne założenia techniczne dotyczące identyfikacji radiowej obejmuje norma ISO/IEC 18000-1:2008 (Information technology – Radio frequency identification for item management – Part 1: Reference architecture and definition of parameters to be standardized), zaś kolejne jej części traktują o komunikacji w poszczególnych pasmach częstotliwości.
LF (Low Frequency) RFID
Ta kategoria obejmuje przede wszystkim popularne karty, breloki, opaski zbliżeniowe i czytniki pracujące na częstotliwości 125 kHz, choć w handlu można (znacznie rzadziej) spotkać też urządzenia korzystające z częstotliwości 134,2 kHz lub nawet z obydwu wymienionych standardów. Tagi LF są także powszechnie spotykane w aplikacjach weterynaryjnych, zwłaszcza znakowaniu zwierząt domowych (psów i kotów) – niewielkie tagi w szklanych kapsułkach aplikuje weterynarz korzystając ze specjalnego narzędzia przypominającego strzykawkę (fotografia 32).

Wytyczne dotyczące technologii LF RFID są przedmiotem normy ISO/IEC 18000-2:2009 (Information technology – Radio frequency identification for item management – Part 2: Parameters for air interface communications below 135 kHz), zaś w odniesieniu do znakowania zwierząt dostępne są także dodatkowe normy:
- ISO 14223-1:2011 – Radiofrequency identification of animals – Advanced transponders – Part 1: Air interface,
- ISO 14223-2:2010 – Radiofrequency identification of animals – Advanced transponders – Part 2: Code and command structure,
- ISO 14223-3:2018 – Radiofrequency identification of animals – Advanced transponders – Part 3: Applications,
przy czym wymienione dokumenty zostały opracowane w oparciu na znacznie wcześniejszych normach ISO 11784:1996 oraz ISO 11785:1996.
HF (High Frequency) RFID
Zdecydowanie najbardziej rozpowszechnione są tagi i urządzenia pracujące na częstotliwości nośnej 13,56 MHz. Tutaj zróżnicowanie aplikacji okazuje się naprawdę duże, a co za tym idzie – powstał także szereg standardów branżowych opisujących m.in. rozmaite protokoły transmisji. Oprócz zastosowań pokrywających się z tagami LF (karty, breloki i opaski, np. do kontroli dostępu czy obsługi legitymacji członkowskich), w tym samym paśmie HF pracują również karty płatnicze, bilety komunikacji miejskiej, tagi do znakowania palet (dostępne także w formie… gwoździ – fotografia 33) i wiele, wiele innych.

W anteny i współpracujące z nimi front-endy NFC wyposażane są obecnie niemal wszystkie produkowane w ostatnich latach urządzenia mobilne. Powszechnie używany skrót NFC (ang. Near-Field Communication) jest najczęściej utożsamiany z RFID 13,56 MHz, a wynika to z faktu, że właśnie w tym paśmie komunikują się urządzenia zdolne do realizacji jednego z trzech trybów pracy:
- Emulacja karty NFC – urządzenie pełni funkcję karty zbliżeniowej, korzystając np. z architektury HCE (ang. Host Card Emulation). W ten sposób dokonywane są płatności zbliżeniowe z użyciem smartfona zamiast klasycznej, plastikowej karty płatniczej.
- Czytnik NFC – urządzenie może odczytywać, a w niektórych przypadkach także zapisywać niewielkie ilości danych w pamięci tagów – tak działają m.in. aplikacje deweloperskie, dostarczane przez producentów układów NFC (np. ST Microelectronics) jako narzędzia do testowania znaczników RFID.
- Komunikacja peer-to-peer – dwa urządzenia aktywne (tj. wyposażone we własne zasilanie), mające moduł NFC, mogą wzajemnie wymieniać dane – przykładowo, istnieje możliwość transferu plików pomiędzy dwoma zbliżonymi do siebie smartfonami.
NFC jest zresztą ciekawym przykładem technologii, która – wyrastając „na ramionach” znanych wcześniej rozwiązań – stopniowo rozwijała się, obudowując kolejnymi normami międzynarodowymi i standardami opracowywanymi zarówno przez konkretnych producentów, jak i ogólnoświatowe organizacje. Oprócz „niskopoziomowego” dokumentu ISO/IEC 18000-3:2010 (Information technology – Radio frequency identification for item management – Part 3: Parameters for air interface communications at 13,56 MHz) mamy zatem szereg standardów obejmujących różne wersje protokołów, stosowanych zarówno w prostych tagach zbliżeniowych, jak i zaawansowanych systemach płatności, komunikacji peer-to-peer, etc. Przykładowo – karty identyfikacyjne pracujące w standardzie ISO/IEC 15693 mają zdecydowanie większy zasięg transmisji (różne źródła podają wartości od kilkudziesięciu centymetrów do 1,5 m) niż układy ISO/IEC 14443 typu A (max. 10 cm, zwykle do około 4 cm), stosowane m.in. w kartach płatniczych – rzecz jasna, celem ograniczenia zasięgu (choć to tylko jedna z wielu różnic) jest zwiększenie bezpieczeństwa transakcji bezgotówkowych.
Wspomniana już rodzina standardów ISO/IEC 14443 (Cards and security devices for personal identification – Contactless proximity objects) obejmuje następujące dokumenty:
- ISO/IEC 14443-1:2018 – Cards and security devices for personal identification – Contactless proximity objects – Part 1: Physical characteristics,
- ISO/IEC 14443-2:2016 – Cards and security devices for personal identification – Contactless proximity objects – Part 2: Radio frequency power and signal interface,
- ISO/IEC 14443-3:2018 – Identification cards – Contactless integrated circuit cards – Proximity cards – Part 3: Initialization and anticollision,
- ISO/IEC 14443-4:2018 – Cards and security devices for personal identification – Contactless proximity objects – Part 4: Transmission protocol.
Norma ISO/IEC 14443 definiuje dwa typy tagów (A i B), różniące się parametrami transmisji na najniższym poziomie – sposobami modulacji fali nośnej, kodowania danych oraz inicjalizacji, przy czym protokół transmisji (opisany w części czwartej) pozostaje ten sam.
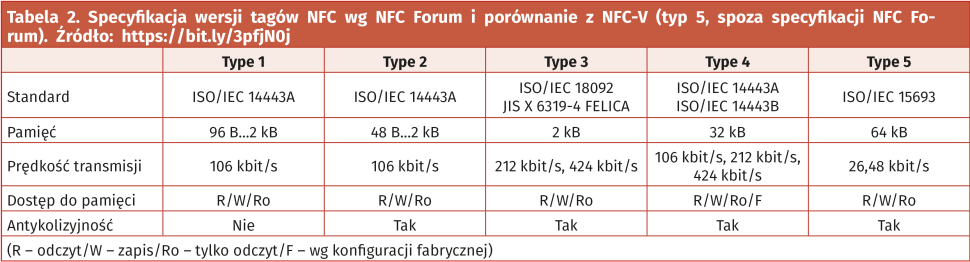
Co więcej – rodzaje tagów określone przez międzynarodową organizację NFC Forum (Type 1…Type 4 – tabela 2) korzystają nie tylko z obydwu wersji 14443A/B, ale także z japońskiego standardu FeliCa (JIS X 6319-4 – Specification of implementation for integrated circuit(s) cards – Part 4: High speed proximity cards) – intensywnie eksploatowanego w Japonii i Singapurze.
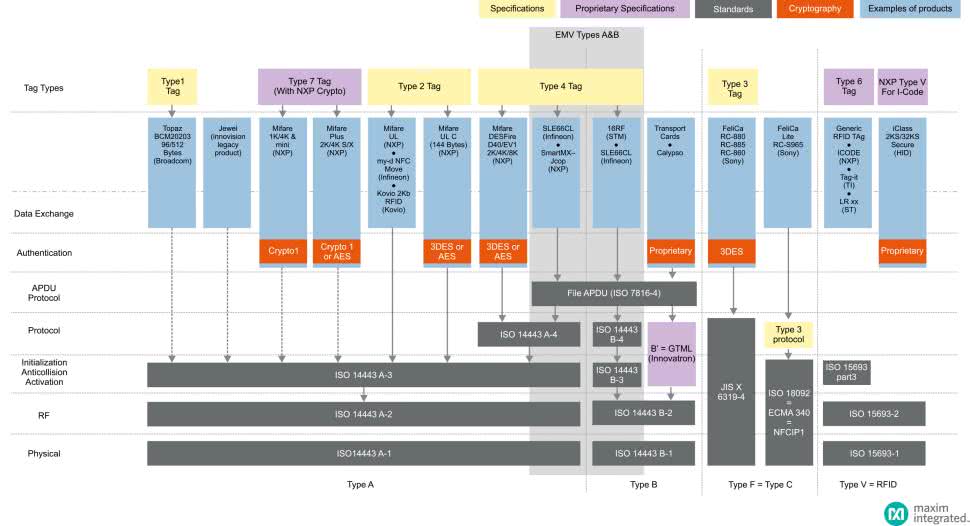
Do opisanych powyżej standardów dochodzą jeszcze kolejne, odpowiadające m.in. za specyfikację kwestii bezpieczeństwa (ISO/IEC 7816-4:2020 – Identification cards – Integrated circuit cards – Part 4: Organization, security and commands for interchange) czy nawiązywania połączeń P2P (ISO/IEC 18092:2013 – Information technology – Telecommunications and information exchange between systems – Near Field Communication – Interface and Protocol (NFCIP-1)). Aby lepiej zrozumieć istotę terminologii stosowanej w świecie technologii NFC, warto uważnie przeanalizować schemat stosu protokołów, pokazany na rysunku 14.
Energy harvesting i tagi dynamiczne
W odniesieniu do RFID 13,56 MHz często mamy do czynienia z zagadnieniem odzyskiwania energii (ang. energy harvesting, w skrócie EH). O ile cała technologia RFID bazuje na przekazie energii poprzez sprzężenie indukcyjne lub transmisję fal radiowych (wszak sposób zasilania tagu w celu jego odczytania to nic innego, jak właśnie przykład energy harvesting), o tyle w przypadku układów przeznaczonych do pracy z czytnikami NFC istnieje możliwość odzyskania części energii dostarczonej przez antenę czytnika do… zasilania zewnętrznych obwodów (rysunek 15). Rzecz jasna, nie ma tutaj mowy o zbyt dużej mocy, ale przy użyciu przemyślanych układów opartych na mikrokontrolerach ultra-low power (np. MSP430 czy STM32L0) jest to jak najbardziej możliwe.

Co więcej, nowsze układy scalone realizujące funkcję konwencjonalnych tagów NFC mogą być także znacznikami dynamicznymi. W tym przypadku pamięć nieulotna (EEPROM), której odczyt i/lub zapis realizuje zewnętrzne urządzenie (specjalizowany czytnik, smartfon, tablet, etc.) za pośrednictwem komunikacji zbliżeniowej, może być także obsługiwana „z drugiej strony”, tj. za pośrednictwem interfejsu lokalnego (najczęściej I²C), przez mikrokontroler znajdujący się w urządzeniu pełniącym funkcję znacznika (rysunek 16).
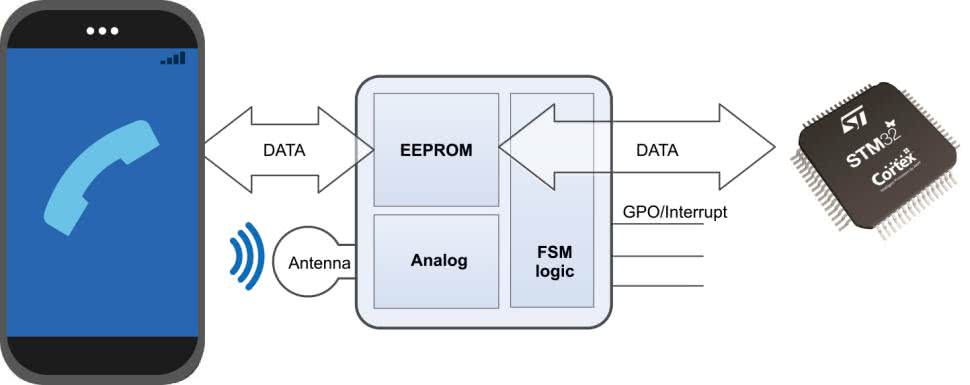
Takie rozwiązanie sprawdza się doskonale zarówno w tagach aktywnych, jak i semi-aktywnych (zwanych często mianem BAP – Battery-Assisted Passive), które – choć wyposażone w wewnętrzne źródło energii – nie mają własnego nadajnika, ale stosują modulację obciążenia do komunikacji z czytnikiem (więcej informacji podamy w dalszej części artykułu), zaś bateria pełni funkcję pomocniczego źródła energii, np. do zasilania wbudowanych w urządzenie czujników. Jeżeli zastosowany front-end RFID zapewnia funkcjonalność EH, to tag dynamiczny może jednocześnie być… tagiem pasywnym (czyli pozbawionym własnego źródła energii, a zamiast niego zawiera najczęściej dość spory kondensator podtrzymujący).
UHF (Ultra-High Frequency) RFID
Choć teoretycznie pasmo rozpatrywane jako UHF obejmuje częstotliwości z zakresu od 300 do 1000 MHz, to w praktyce stosuje się podzakresy leżące w paśmie ISM: 433 MHz oraz 860–960 MHz. Jak widać, są to popularne zakresy częstotliwości stosowanych w rozmaitych systemach łączności radiowej, mamy zatem do czynienia z technologią diametralnie inną niż w przypadku omówionych wcześniej tagów LF i HF. Inne są nie tylko zasięgi transmisji (wielokrotnie większe niż dla technologii zbliżeniowych), ale także rozwiązania techniczne – zamiast anten spiralnych lub pętlowych, w czytnikach i tagach UHF występują najczęściej anteny ceramiczne lub mikropaskowe (fotografia 34).

Intensywny rozwój technologii UHF RFID w ostatnich latach jest możliwy dzięki upowszechnieniu standardu EPC Gen 2 (obecnie w wersji 2.1) – z dokumentem można zapoznać się za darmo w Internecie, na stronie wspomnianej wcześniej organizacji GS1 (https://bit.ly/3C0oF1b). Norma przewiduje rozmaite tryby pracy czytników, obejmując także sytuacje, w których w niewielkiej przestrzeni pracuje jednocześnie wiele takich urządzeń – wszak tutaj zasięg nie jest już ograniczony do pola bliskiego (jak w przypadku RFID LF i HF), gdyż wszystkie systemy UHF pracują w polu dalekim. Co więcej – standard EPC Gen 2 obejmuje także techniki pozwalające na odczyt wielu tagów w tym samym momencie, co umożliwia szybką inwentaryzację stanów magazynowych lub np. zestawów oznakowanych tagami narzędzi chirurgicznych. Dla zwiększonego bezpieczeństwa norma ustala także wytyczne dotyczące metod zabezpieczeń z użyciem haseł, kluczy szyfrujących, etc.
Od strony niskopoziomowej istotne dla branży UHF RFID są następujące dokumenty:
- ISO/IEC 18000-6:2013 – Radio frequency identification for item management – Part 6: Parameters for air interface communications at 860 MHz to 960 MHz General,
- ISO/IEC 18000-61:2012 – (…) Parameters for air interface communications at 860 MHz to 960 MHz Type A,
- ISO/IEC 18000-62:2012 – (…) Parameters for air interface communications at 860 MHz to 960 MHz Type B,
- ISO/IEC 18000-63:2021 – (…) Parameters for air interface communications at 860 MHz to 960 MHz Type C.
Warto także zwrócić uwagę na nomy ISO/IEC 15961 i ISO/IEC 15962 (protokół wymiany danych), ISO/IEC 15963 (identyfikatory unikalne), ISO/IEC 18000-1 (o tym dokumencie pisaliśmy już wcześniej) oraz ISO/IEC 19762 (nomenklatura zharmonizowana) i ISO/IEC 29167-1 (bezpieczeństwo).
Technologie RFID LF i HF vs UHF – porównanie metod komunikacji tag
Jak wspomnieliśmy wcześniej, poszczególne techniki RFID różnią się pomiędzy sobą w kwestii metod przesyłania danych od tagu do czytnika, a najbardziej istotne różnice widać przy porównaniu urządzeń LF i HF z systemami UHF. W przypadku tych pierwszych mamy do czynienia ze sprzężeniem indukcyjnym (magnetycznym) pomiędzy antenami, tworzonymi przez jedno- lub wielozwojowe cewki (rysunek 17). Sygnał nadawany przez czytnik zasila tag aż do momentu jego „wybudzenia” (uruchomienia układu sterującego), po czym tag odbiera niezbędne dane z czytnika i przesyła informację zwrotną na drodze modulacji obciążenia swojej anteny (np. przez dołączanie i odłączanie rezystancji zwiększającej pobór prądu bądź pojemności, co skutkuje odstrojeniem układu rezonansowego). Te niewielkie zmiany obciążenia przekładają się na modulację napięcia zmiennego panującego na antenie czytnika, a to pozwala na odczytanie sygnału „nadanego” przez tag. Warto zwrócić uwagę, że nie mówimy tutaj o nadajniku jako takim – modulowane jest tylko obciążenie, widziane od strony front-endu czytnika.

W przypadku systemów RFID pracujących w polu dalekim (głównie UHF, ale także rozwiązań mikrofalowych) antena czytnika nie może już bezpośrednio „odczuwać” zmian obciążenia, przenoszonych przez pole bliskie – fala radiowa wysłana przez nadajnik jest propagowana w otaczającą przestrzeń i nie powraca do nadajnika, jeżeli nie nastąpi silne jej odbicie lub… zjawisko rozpraszania wstecznego (ang. backscatter). To ostatnie zachodzi szczególnie skutecznie w sytuacji, gdy fala natrafi na układ z dobrze dopasowaną (do częstotliwości nośnej) anteną. Jeżeli jednak front-end RF zostanie odstrojony (np. przez dołączenie obciążenia rezystancyjnego), skuteczna powierzchnia odbicia (ang. RCS – Reflection Cross-Section) ulega zmianie, co wpływa na moc sygnału powracającego do czytnika – patrz rysunek 18. Praca w trybie modulowanego rozpraszania wstecznego umożliwia uzyskanie znacznie większego zasięgu w przypadku systemów UHF, w porównaniu do tagów i czytników LF oraz HF.

Podsumowanie
Technologie identyfikacji radiowej i optycznej ulegają ciągłym przemianom – starsze, nieefektywne techniki są wypierane przez nowsze metody i urządzenia. Zarówno w przypadku kodów kreskowych, jak i znaczników RFID podstawowe założenia w obu grupach rozwiązań pozostają niezmienne od lat – kody 1D i 2D przechowują informacje w postaci kontrastowych, geometrycznych oznaczeń, zaś tagi RFID – w formie ciągu znaków zapisanych w pamięci półprzewodnikowej. W jednym i drugim przypadku – dzięki zastosowaniu automatycznych czytników – dostęp do informacji jest natychmiastowy i całkowicie odporny na błędy grube, których nie sposób uniknąć w przypadku przepisywania i/lub odczytywania identyfikatorów przez człowieka.
Na tych podstawowych założeniach kończy się zakres aspektów niezmiennych – modyfikacjom ulegały i w dalszym ciągu ulegają niemal wszystkie pozostałe zagadnienia metod sprzętowej identyfikacji osób i obiektów. W przypadku kodów kreskowych prawdziwą rewolucję stanowiło wprowadzenie kodów dwuwymiarowych, a wymyślne techniki zapisu danych i korekcji błędów pozwalają na znaczne zwiększenie niezawodności, nawet w sytuacjach, gdy etykieta z kodem jest uszkodzona, niekompletna lub mało kontrastowa. Trudno powiedzieć, co czeka nas w przyszłości – konwencjonalne kody kreskowe takie jak EAN-13 czy UPC-A mają się doskonale i nic nie wróży szybkiego wycofania ich z rynku na rzecz nowszych rozwiązań. Kody QR oraz Data Matrix także pozostają w ciągłym użyciu i coraz trudniej jest znaleźć opakowanie produktu (lub produkt sam w sobie), na którym nie ma choć jednego takiego oznaczenia. Próby wprowadzenia kodów wielokolorowych jak na razie spaliły na panewce, o czym przekonał się chociażby Microsoft na przykładzie kodu HCCB.
Największe zmiany zachodzą zatem w zakresie czytników – użytkownicy prywatni najczęściej stosują urządzenia mobilne (wyposażone w odpowiednie aplikacje) do obsługi wszechobecnych kodów QR, zaś zakłady przemysłowe (w których identyfikacja optyczna stanowi jeden z kluczowych elementów systemu kontroli jakości) decydują się na implementację zaawansowanych, bardzo szybkich czytników o wysokiej rozdzielczości i/lub dalekim zasięgu. Istnieją nawet doniesienia o stosowaniu… soczewek płynnych, umożliwiających automatyczne przestrajanie optyki w celu obsługi etykiet zarówno blisko, jak i daleko położonych od czytnika.
W świecie RFID zmiany zachodzą znacznie szybciej i są zakrojone na dalece szerszą skalę. Po etapie świetności systemów niskiej częstotliwości (głównie 125 kHz) popularność zyskały urządzenia i tagi NFC, a elektroniczne systemy płatności zbliżeniowych, bazujące na tej technologii, zaczęły sukcesywnie wypierać klasyczną gotówkę. Mało tego – techniki NFC zyskały nawet wsparcie legislacyjne poprzez ustanowienie obowiązku posiadania terminali płatniczych przez podmioty handlowe. Dziś moduł NFC jest wbudowany w niemal każdy nowy smartfon i wiele innych urządzeń mobilnych, słuchawek, gadżetów IoT, etc. Technologie UHF szturmem wdarły się w świat logistyki, a już zaczynają kolonizować sale operacyjne, szpitalne magazyny sprzętu medycznego, fabryki samochodów, hurtownie i niezliczoną ilość innych obszarów aplikacyjnych. A to dopiero początek rewolucji, gdyż to właśnie w tagach i czytnikach UHF upatruje się możliwości dokonania przełomu w automatycznej identyfikacji i śledzeniu obiektów. Równolegle trwają prace nad identyfikacją mikrofalową w paśmie S (2,45 GHz), która doczekała się już nawet dedykowanej normy (ISO/IEC 18000-4). A co jeszcze przyniesie przyszłość? Z pewnością udział RFID w naszym codziennym życiu będzie sukcesywnie rósł, coraz bardziej łącząc siły – podobnie jak większość współczesnych nam obszarów technologii – z rozwiązaniami IoT i IIoT.
inż. Przemysław Musz, EP












